
")
A study on multi-scale kernel optimisation via centred kernel-target alignment
María Pérez-Ortiz, Pedro Antonio Gutiérrez, Javier Sánchez-Monedero and César Hervás-Martínez
Department of Computer Science and Numerical Analysis, University of Córdoba, Rabanales Campus, C2 building, 14004 - Córdoba, Spain.
e-mail: Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
, Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
, Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
, Esta dirección de correo electrónico está siendo protegida contra los robots de spam. Necesita tener JavaScript habilitado para poder verlo.
This page provides supplementary material for the experimental results in the paper entitled A study on multi-scale kernel optimisation via centred kernel-target alignment submitted to Neural Processing Letters.
Abstract of the paper
Kernel mapping is one of the most widespread approaches to intrinsically deriving nonlinear classifiers. With the aim of better suiting a given dataset, different types of kernels have been proposed and different bounds and methodologies have been studied to optimise these kernels. We focus on the optimisation of a multi-scale kernel, where a different width is chosen for each feature. This idea has been barely studied in the literature, although it has been shown to achieve better performance in the presence of heterogeneous attributes. The large number of parameters in multi-scale kernels makes it computationally unaffordable to optimise them by applying traditional cross-validation. Instead, an analytical measure known as centred kernel-target alignment (CKTA) can be used to align the kernel to the so-called ideal kernel matrix. This paper analyses and compares this and other alternatives, providing a review of the state-of-the-art in kernel optimisation and some insights into the usefulness of multi-scale kernel optimisation via CKTA. When applied to the binary support vector machine paradigm (SVM), the results using $24$ datasets show that CKTA with a multi-scale kernel leads to the construction of a well-defined feature space and simpler SVM models, provides an implicit filtering of non-informative features and achieves robust and comparable performance to other state-of-the-art methods even when using random initialisations. Finally, we derive some considerations about when a multi-scale approach could be, in general, useful and propose a distance-based initialisation technique for the gradient-ascent method, which shows promising results.
The additional information provided for the experimental section is the following:
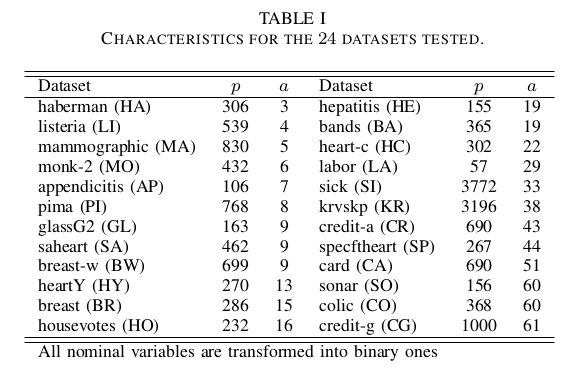
- Datasets: The performance of the methods is analysed by using a set of 24 publicly available datasets. The main characteristics of these datasets can be seen in Table 1, where the name, number of patterns, attributes, classes and distribution were reported. Regarding the experimental setup, the datasets have been partitioned by a stratified 10-fold procedure. The following link contains the whole set of data partitions in Weka, LibSVM and matlab formats.
 10fold-binary-datasets.zip
10fold-binary-datasets.zip
- Detailed results: The mean results obtained for each dataset and methodology tested in the experimental study can be seen in the following link. The performance of each one of the methodologies tested can be seen in a different file (.csv or .xls) reporting Accuracy, number of support vectors and training and testing centered alignment values. mean-results.zip